Construir una analítica sobre lo que ha ocurrido en twitter en una conversación alrededor de un #hashtag no es algo trivial o que se analice con “que usuario ha utilizado más el #hashtag”, cosa que se puede analizar a través de twittreach (al menos los últimos 50 twitts en la versión gratuita, pagando todos los que queramos), o bien el uso intensivo de determinado #hashtag lo podemos ver en topsy.
Pero estos informes son pequeñas gotas sobre el uso de un #hashtag, para hacer un análisis más a fondo recomiendo descargar los datos en NodeXL, exportarlo a un formato de lectura para Gephi y hacer el análisis con esta herramienta. Esto proporciona la máxima profundidad de una conversación.
En R se pueden hacer los mismos análisis que en Gephi aunque de forma más compleja y complicada. Igualmente R nos puede servir para hacer análisis de primera mano de una determinada conversación.
Este script nos proporciona tres gráficas una con los usuarios más activos, otra con los usuarios más retuiteados, y otra con los usuarios más citados. Esto nos permite, sin necesidad de utilizar análisis más avanzados conseguir una fotografía de los usuarios más interesantes (los más parlanchines, los que son más interesantes para otros usuarios, y aquellos a los que hablan más). Esto nos permite una foto rápida de los usuarios.
Respecto a las herramientas gratuitas que circulan por internet tiene algunas ventajas. Es preferible muchas veces saber que usuario ha sido más retuiteado, aunque no nos proporciona la capacidad real de impacto (eso requiere un análisis más profundo como el que nos proporciona NodeXL + Gephi) sí que nos da de una forma mucho más rápida y sin necesidad de conocer el uso de estas herramientas una foto de que usuarios son los que han dicho cosas más interesantes (y por tanto han sido retuiteados) o los que tienen una comunidad alrededor que este tema les puede interesar. Es una foto, de corto alcance pero ilustrativa de quienes pueden ser los usuarios más interesantes de esta conversación.
Las gráficas que se obtienen son muy parecidas a estas (ejemplo de análisis de los últimos 200 twitts alrededor del hashta #infographic)

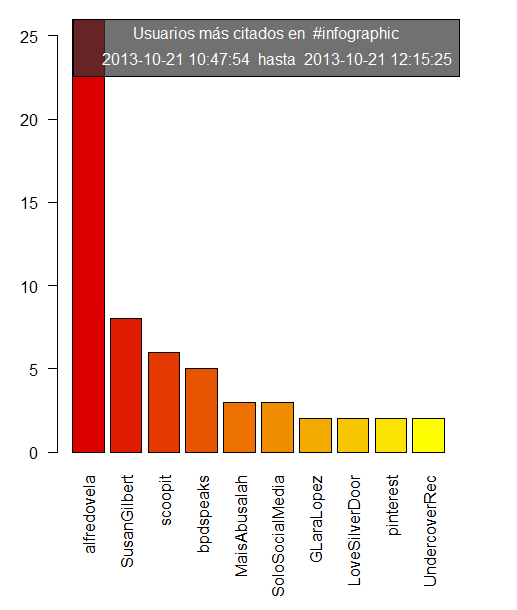
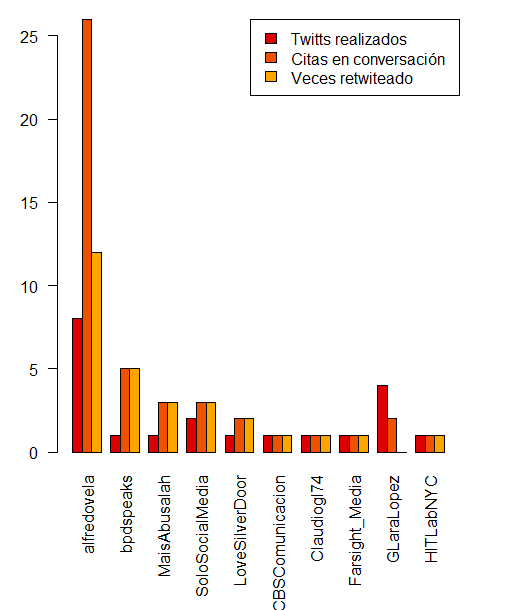
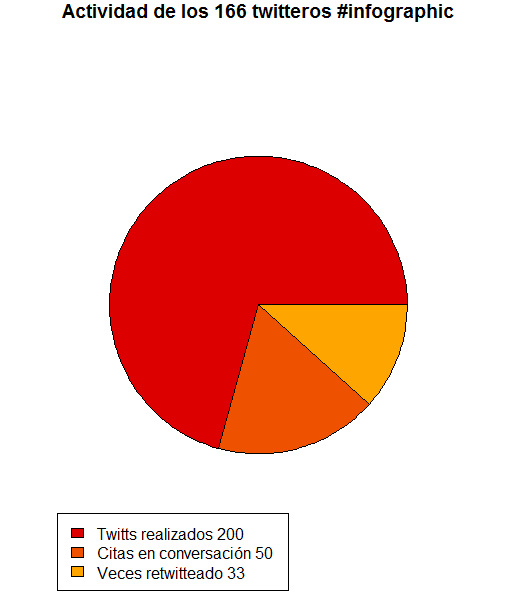
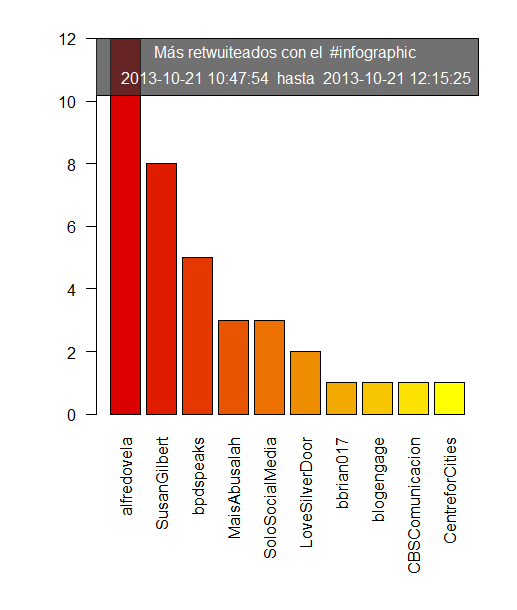
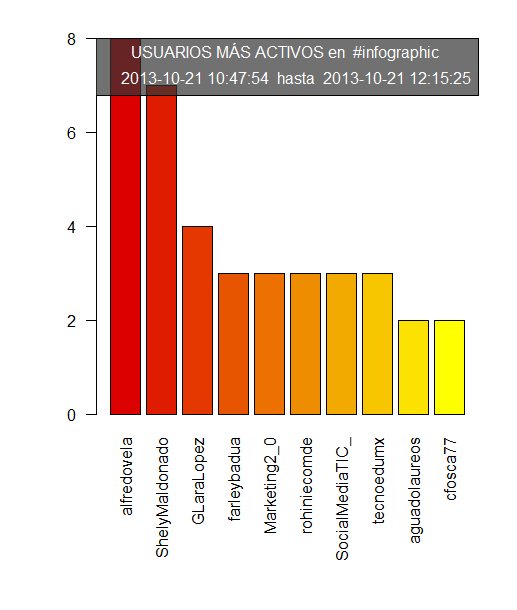
Y un archivo .txt que genera este tipo de tablas
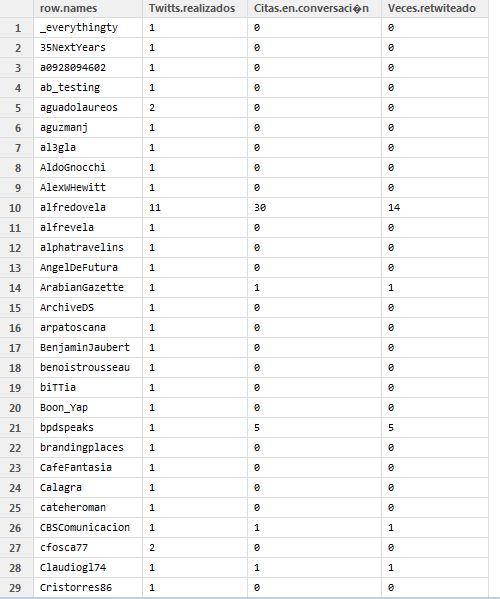
El script de R es este y puede ser copiado sin demasiados problemas, y ser utilizado por cualquier usuario de R que sepa tan sólo los rudimentos de abrir un script, con lo cuál puede instalarse en una máquina que puedan utilizar varios usuarios sin conocimientos avanzados de R. Como toda analítica de R, lo complicado es conseguir tu fichero . RData acreditado (en el propio Script explico como obtenerlo, recordar que estamos funcionando con la API de twitter 1.1).
Una vez logrado instalar el .RData el uso es trivial y el mismo scritp te va a ir pidiendo las variables (hashtags, número de twitts, si limitas el análisis a una zona geográfica concreta) necesarias.
hashtag.R
############# Objetivo del programa ###############################
## Nombre: Usuarios más retwitteados en un hashtag.
## Objetivo: Función que extrae que usuarios son más retwiteados
## en una determinada conversación de twitter y los muestra
## en un gráfico de barras, a la vez que guarda un fichero
## txt con el listado completo.
##
## Descripción: Introduzco una string de búsqueda de twitter
## lo más normal que sea un #hashtag y obtengo una gráfica
## de barras con los usuarios que más han twitteado
## y aquellos que han sido más retwitteados y un listado
## en txt para exportar a otras herramientas con el listado
## completo.
##
## Output: Cuatro imágenes de gráfica de barras, una nube de tags
## y un fichero.txt
##
## Forma de utilizar:
# source(hashtag.R)
## Sistema en el que está testeado:
## R-Studio con funcionando bajo Windows-XP SP3
## Válido para la API de Twitter 1.1
###################################################################
## Cargo las librerías y las credenciales de identificación
## con twitter
require(twitteR)
library(stringr)
library(wordcloud)
library(RCurl)
library(tm)
options(RCurlOptions = list(cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl")))
u = "https://raw.github.com/tonybreyal/Blog-Reference-Functions/master/R/bingSearchXScraper/bingSearchXScraper."
x = getURL(u, cainfo = system.file("CurlSSL", "cacert.pem", package = "RCurl"))
load("rcredenciales.RData") ## El tener tu propio .RData autentificado es una parte compleja
registerTwitterOAuth(tw)
###################################
### Definición de las variables ###
##
## hashtag es una string
## describe un hashtag o un string
## de búsqueda en twitter
hashtag = readline("¿Cuál es el hashtag que quieres analizar? ")
# pequeño código que evita dejar vacía esta variable
while (hashtag =="") hashtag = readline("Por favor, define un hashtag para analizar ")
## TweetNumber es un "Number"
## Es el número de twitts en los que quiero ahondar
TweetNumber = readline("Cuantos tweets quieres analizar? ")
TweetNumber = as.numeric(unlist(strsplit(TweetNumber, ",")))
##
## geo es una string especial de localización geográfica
## tiene tres componentes, 2 numéricas que indican las coordenadas
## y una tercera formada por un número y la terminación "km" o "mi"
## indica un rádio de búsqueda
geog = readline("Ámbito geográfico, dejar vacio si no se quiere colocar, ejemplo:41.378476,2.1701334,150km ")
if (geog=="") geog=NULL
## Ejemplo búsqueda geográfica "41.378476,2.1701334,150km"
nombredelarchivo = readline("Nombre del archivo donde se quiere grabar ")
while (nombredelarchivo =="") nombredelarchivo = readline ("No dejes vacío este campo, o no podré grabar el archivo ")
#########################################
## Ejecución del vaciado de datos
## análisis.
## Input: vairables: hashtag, tweetnumber, geo
## Output: Un data frame con usuarios y números de RT
#########################################
rdmTweets = searchTwitter(hashtag, n=TweetNumber, geo=geog)
#Creamos un Data Frame con los resultados
df = do.call("rbind", lapply(rdmTweets, as.data.frame))
####################################################
## PARTE 1: LOS USUARIOS MÁS ACTIVOS
###################################################
#########################################
## Transformación a tabla del data frame
## Input: df (data frame)
## Output: counts (table) con el número
## de twitts realizados por cada usuario
#########################################
counts=table(df$screenName)
##########################
# Hago un primer plot, de texteo, antes
# de ordenarlo
#########################
barplot(counts)
###########################
## Función que ordena una tabla
## Ordena de mayor a menor el
## listado de usuarios más RT
##
## Input: count (tabla)
## Output: cc (tabla)
############################
cc = sort(counts, decreasing=T)
###########################
## Función paleta de colores
## Creamos una paleta de colores chula
##
## Input: colores RGB y un número de degradados
## Output: Paleta entre los colores de N degradados
##################################
degradado = function (color1, color2, degradados)
{
library(grDevices)
palete = colorRampPalette(c(color1, color2))
palete (degradados)
}
paleta = degradado ("#DD0000", "#FFFF00", 10)
###########################
## Comienzo a trazar el plot definitivo
##########################
################################################
## Trabajos previos para conseguir algunos datos que
## irán en el plot
## transformo la lista de twitts en una forma más manejable
tweetsdf = twListToDF(rdmTweets)
## creo la función last para sacar la última entrada
## y su fecha
last = function(x) { tail(x, n = 1) }
###############################
## Dibujo el plot
###############################
par(mar=c(10,5,2,2), bg="white") ## Establezco los márgenes para ajustar la imagen
barplot(cc[1:10],las=2,cex.names =1, col=paleta) ## Dibujo un plot de los 10 usuarios TOP
## Incluyo una leyenda con los datos de la búsqueda de cara a poder tener una visión
## de que tipos de datos estoy publicando
legend("topright", title=paste("USUARIOS MÁS ACTIVOS en ",hashtag, sep=""), legend=paste(last(tweetsdf$created), " hasta ",tweetsdf$created[1]), text.col="#FFFFFF", bg="#333333B2", inset=0)
###########################
## PARTE 2: USUARIOS MÁS RETWITTEADSO
#########################
## Hago pausa ##
continue = readline("Graba el plot y continúa con el script pulsando (1) ")
while (continue != "1") continue=readline("Graba el plot y continúa con el script pulsando (1) ")
## Esta pausa es para que el usuario pueda grabar el plot de
## usuarios más activos
# Pequeña función que elimina carácteres que pueden generar problemas
# en el análisis.
df$text=sapply(df$text,function(row) iconv(row,to='UTF-8'))
# Función que elimina las @ de los usuarios
trim = function (x) sub('@','',x)
# Extraigo los usuariso que han sido retwitteados
df$rt=sapply(df$text,function(tweet) trim(str_match(tweet,"^RT (@[[:alnum:]_]*)")[2]))
# Genero un Data Frame de la tabla con el que luego elaboraré el barplot
df.ordered = as.data.frame(table(df$rt), row.names=TRUE)
# Lo ordeno de mayor a menor
order.freq = order(df.ordered$Freq, decreasing=T)
# Creo el barplot de los 10 usuarios más retuiteados
barplot(df.ordered$Freq[order.freq][1:10], las=2,cex.names =1, col=paleta, names.arg=rownames(df.ordered)[order.freq][1:10])
# Añado una leyenda, igual que en la parte 1
legend("topright", title=paste("Más retwuiteados con el ",hashtag, sep=""), legend=paste(last(tweetsdf$created), " hasta ",tweetsdf$created[1]), text.col="#FFFFFF", bg="#333333B2", inset=0)
## Hago pausa una segunda pausa ##
continue = readline("Graba el plot y continúa con el script pulsando (2) ")
while (continue != "2") continue=readline("Graba el plot y continúa con el script pulsando (2) ")
#######################
## PARTE 3 : USUARIOS QUE MÁS HAN SIDO CITADOS
## EN UNA CONVERSACIÓN EN ESTE HASHTAG
#######################
# Extraigo los usuarios citados en los mensajes
df$to=sapply(df$text,function(tweet) str_extract(tweet,"(@[[:alnum:]_]*)"))
# Creo un mensaje de error y un mecanismo de parada si realmente
# no hay usuarios citados en esta conversación
## df$to[is.na(df$to)] = 0
# Limpio "df$to" de carácteres que estorban (como las @)
df$to=sapply(df$to,function(name) trim(name))
# Creo un data frame de df$to para facilitar el trabajo
# con plots
df.2 = as.data.frame(table(df$to), row.names=TRUE)
# Ordeno de mayor a menor el data frame
order2.freq = order(df.2$Freq, decreasing=T)
par(mar=c(8,3,1,3))
# Hago el barplot de los usuarios más citados
barplot(df.2$Freq[order2.freq][1:10], las=2,cex.names =1, col=paleta, names.arg=rownames(df.2)[order2.freq][1:10])
# Incluyo una leyenda
legend("topright", title=paste("Usuarios más citados en ",hashtag, sep=""), legend=paste(last(tweetsdf$created), " hasta ",tweetsdf$created[1]), text.col="#FFFFFF", bg="#333333B2", inset=0)
##############################
## PARTE 4 GUARDO EL ARCHIVO
##################################
### Renombro columnas en todos mis data frames
colnames(df.ordered) = c("Veces retwiteado")
colnames(df.2) = c("Citas en conversación")
cc = as.data.frame(cc)
colnames(cc) = c("Twitts realizados")
### Comienzo a juntarlos, renombrar columnas y borrar las sobrantes
total1 = merge(cc,df.2, by="row.names", all.x=T)
rownames(total1) = total1[,1]
drops = c("Row.names")
total1 = total1[,!(names(total1) %in% drops)]
total = merge(total1,df.ordered, by="row.names", all.x=T)
rownames(total) = total[,1]
total = total[,!(names(total) %in% drops)]
## Elimino los NA por 0 para quedarme una tabla más útil
total[is.na(total)] = 0
#############################################
# Ejecución de la función de salvado en TXT
# Input: matriz df, nombredelarchivo
# Output: Un ficher txt con los usuarios y sus RT
######################################
nombredelarchivo = paste(nombredelarchivo,".txt", sep="")
write.table(total, file=nombredelarchivo)
engagement = total[,2]+total[,3]
total ["Engagement"] = engagement
order.freq = order(total[,4], decreasing=T)
paleta2 = degradado ("#DD0000", "orange", 3)
#### Hago un último plot ######
barplot( rbind(total[,1][order.freq][1:10],total[,2][order.freq][1:10],total[,3][order.freq][1:10]), names=row.names(total)[order.freq][1:10], beside=TRUE, las=2,cex.names =1, col=paleta2)
legend("topright", legend=names(total)[1:3], fill=paleta2)
#########################
## PARTE 5, HAGO UN CHART DE LA CONVERSACIÓN
#######
## Hago otra pausa ##
continue = readline("Graba el plot y continúa con el script pulsando (4) ")
while (continue != "4") continue=readline("Graba el plot y continúa con el script pulsando (4) ")
#### Resumen de la conversación ###
a = colSums(total)
b= c(nrow(total), a)
b= b[-5]
print("Resumen de la actividad en la conversación")
print(b)
names(b) = c("Participantes", "Twitts realizados", "Citas en conversación", "Veces retwitteado")
lbls = paste(names(b),b, sep=" ")
par(mar=c(1,3,1,3), bg="white")
pie(b[2:4], main=paste("Actividad de los ",b[1]," twitteros ",hashtag, sep=""), col=paleta2, label="")
legend("bottomleft", legend=lbls[2:4], fill=paleta2)
## Hago otra pausa ##
continue = readline("Graba el plot y continúa con el script pulsando (5) ")
while (continue != "5") continue=readline("Graba el plot y continúa con el script pulsando (5) ")
#############################################
## PARTE 6, CREO UNA NUBE DE TAGS
#############################################
#####################################################
## Limpieza del texto de carácteres incompatibles o contenidos
## sin valor semántico (preposiciones, etc..)
##
## R gestiona mal los carácteres especiales del castellano y catalá
## Estos scripts sustituyen carácteres en castellano / catalán.
## Si el script.R no está grabado con el Encoding adecuado
## se ha de ejecutar el código en la consola a trozos a partir de
## aquí
## Por ejemplo: La codificación del script ha de ser Windows para usuarios Windows
## y no UTF-8 o algún ISO
########################################################3
mach_text = sapply(rdmTweets, function(x) x$getText())
########## Establezco el sistema local del idioma (solo para usuarios Windows)
Sys.setlocale("LC_CTYPE", "spanish")
## Función no definida (para evitar problemas de ejecución
## he preferido ejecutar una por una las substituciones)
##
## Transforma una Lista() en otra Lista()
## Objetivo: Sustituye los carácteres mal descargados por
## carácteres latinos que los scripts puedan leer sin problemas
mach_text = gsub(hashtag, "", mach_text) ## elimino el propio hashtag
mach_text = tolower(mach_text)
mach_text = gsub("ã¡", "a", mach_text)
mach_text = gsub("ã©", "e", mach_text)
mach_text = gsub("ã³", "o", mach_text)
mach_text = gsub("ãº", "u", mach_text)
mach_text = gsub("ã±", "ñ", mach_text)
mach_text = gsub("ã¨", "e", mach_text)
mach_text = gsub("ã²", "o", mach_text)
mach_text = gsub("ã", "i", mach_text)
## Se define la función clean.text
## Transforma una Lista() en otra Lista()
## Objetivo: Filtra palabras (evita URL, @usuarios, etc...)
##
clean.text = function(x)
{
# tolower
x = tolower(x)
# remove rt
x = gsub("rt", "", x)
# remove at
x = gsub("@\\w+", "", x)
# remove punctuation
x = gsub("[[:punct:]]", "", x)
# remove numbers
x = gsub("[[:digit:]]", "", x)
# remove links http
x = gsub("http\\w+", "", x)
# remove tabs
x = gsub("[ |\t]{2,}", "", x)
# remove blank spaces at the beginning
x = gsub("^ ", "", x)
# remove blank spaces at the end
x = gsub(" $", "", x)
return(x)
}
mach_text = clean.text(mach_text)
mach_text = gsub("mas", "", mach_text) ## elimino la palabra "mas"
############################################
## Transformamos la lista de textos en vectores y
## luego en una matriz
##############################################3
## Creamos un Corpus vectorial con los twitts
## Transformamos una Lista () en un Corpus de vectores
mach_corpus = Corpus(VectorSource(mach_text)
)
## Creamos una matriz, limpiamos los elementos que nos sobran (los artículos, etc..)
## Transformamos un Corpus en una matriz
# create document term matrix applying some transformations
tdm = TermDocumentMatrix(mach_corpus, control = list(removePunctuation = TRUE, stopwords = c(stopwords("spanish"), stopwords("catalan"), "@"), removeNumbers = TRUE, tolower = TRUE))
# define tdm as matrix
m = as.matrix(tdm)
##################################################################
######### Contamos la frecuencia de las palabras utilizadas #######
##############################################################3
# get word counts in decreasing order
word_freqs = sort(rowSums(m), decreasing=TRUE)
# create a data frame with words and their frequencies
dm = data.frame(word=names(word_freqs), freq=word_freqs)
# plot wordcloud
wordcloud(dm$word, dm$freq, random.order=FALSE, max.words=25, colors=brewer.pal(8, "Dark2"))
######### Creo una nube de tags y lo transformo en el PNG #####################
## Construyo una paleta de colores
degradado = function (color1, color2, degradados)
{
library(grDevices)
palete = colorRampPalette(c(color1, color2))
palete (degradados)
}
mipaleta = degradado ("#DD0000", "#FFFF00", 25)
## Dibujo la nube de palabras
par(bg = "black") ## Establezco un fondo negro
wordcloud(dm$word, dm$freq, random.order=FALSE, colors=mipaleta) ## construye la nube de tags
legend("bottom", title=paste("Nube de tags del ",hashtag, " analizados ", TweetNumber, " tweets", sep=""), legend=paste("Tweets desde ",last(tweetsdf$created), " hasta ",tweetsdf$created[1]), text.col="#FFFFFF", bg="#333333B2", inset=0)
Luego no hay nada más que exportar el plot a un fichero PNG que es trivial desde el panel de control de R o R-Studio e importar el fichero .TXT a cualquier editor de hojas de cálculo para una gestión más detallada.
Algunos usos avanzados
En lugar de analizar un hashtag podemos analizar un string de búsqueda cualquiera de twitter (aquí hay una explicación clara de como construirlos) y nos permitiría ver que usuarios han sido más retuiteados entre los que hayan hecho twitts que coinciden con nuestro criterio de búsqueda, así podemos analizar conversaciones de twitter aunque no haya habido un #hashtag si sabemos definir bien un string de búsqueda que pueda definirla.
Un trabajo manual con el fichero.txt que se puede hacer es ordenar los usuarios, no por número de twitts realizados sino por comunidades. Aunque no utilicemos Gephi y NodeXL si conocemos algo del tema que estamos analizando, podemos identificar, por ejemplo, los 50 usuarios más retuiteados y en nuestra tabla de Excel agruparlos por comunidades que tengamos identificadas previamente. Luego podemos hacer una gráfica de comunidades y ver cuál ha sido más activa. Igualmente un uso más fino requiere Gephi ya que puede ser que determinada comunidad haya sido muy activa retuiteándose mútuamente pero no conseguir mover sus contenidos más allá de un círculo muy pequeño.
Más artículos relacionados
 Creación con R de dendogramas semánticos y clústers de conversaciones en twitter
Creación con R de dendogramas semánticos y clústers de conversaciones en twitter Dibujar la nube de tags de un usuario de twitter con R
Dibujar la nube de tags de un usuario de twitter con R Análisis del debate en twitter de #sumantxbcn y #primariesobertesbcn: Las primarias interesan a los activistas y el público interno, aún no al externo.
Análisis del debate en twitter de #sumantxbcn y #primariesobertesbcn: Las primarias interesan a los activistas y el público interno, aún no al externo. Análisis de la conversación de los independentistas en twitter al anuncio de la consulta
Análisis de la conversación de los independentistas en twitter al anuncio de la consulta


Muchisimas gracias por tu aporte, me ha sido de gran ayuda.
Te quería preguntar una duda. Como sería el comando para extraer las URL’s que contienen los tweets y que estas me aparezcan en el txt junto con los otros tres parámetros?
Muchas gracias por adelantado